线性回归
有监督学习中,标记值为离散类型,则为分类问题;如果是连续值,则为回归。样本非线性,参数线性。
模型描述
模型介绍
$$y=ax+b$$
对于两个变量:
$$h_\theta \left ( x \right ) =\theta _0 + \theta _1 x_1+\theta _2 x_2$$
扩展到N维变量
$$h_\theta \left ( x \right ) =\sum _{i=0}^{n}{\theta _i}x_i=\theta ^T x$$
加上误差项可表示为以下形式:
$${y^\left ( i \right ) }= {\theta ^ T x^\left ( i \right )} + {\varepsilon ^ \left ( i \right )}$$
其中$${\varepsilon ^ \left ( i \right )}$$是独立同分布服务均值为0,误差为某定值$$\sigma ^2$$的高斯分布。
求解解析式
目标函数:$$J\left ( \theta \right )=\frac{1}{2}\sum^m_{i=1}\left ( h_\theta{\left ( x^{\left ( i \right )} \right )} - y^{\left ( i \right )} \right )^2 = \frac{1}{2}\left ( X\theta - y \right )^T\left ( X\theta - y \right )$$
梯度:$$\Delta _\theta J\left ( \theta \right ) = X^T X \theta - X^T y$$
求驻点,得:$$\theta = \left ( {X^T X} \right )^{-1} X^T y$$
若$${X^T X}$$不可逆或防止过拟合,增加扰动,得:$$\theta = \left ( {X^T X + \lambda I} \right )^{-1} X^T y$$
线性回归的复杂度惩罚因子
L2-norm: $$J\left ( \vec{\theta} \right )=\frac{1}{2}\sum^m_{i=1}\left ( h_\theta{\left ( x^{\left ( i \right )} \right )} - y^{\left ( i \right )} \right )^2 + \lambda \sum_{j=1}^{n}\theta_j^2$$, Ridge回归(1970)
L1-norm:
$$J\left ( \vec{\theta} \right )=\frac{1}{2}\sum^m_{i=1}\left ( h_\theta{\left ( x^{\left ( i \right )} \right )} - y^{\left ( i \right )} \right )^2 + \lambda \sum_{j=1}^{n} \left | \theta_j \right |$$, LASSO(Least Absolute Shrinkage and Selection Operator), LARS算法解决LASSO计算
Elastic Net:
$$J\left ( \vec{\theta} \right )=\frac{1}{2}\sum^m_{i=1}\left ( h_\theta{\left ( x^{\left ( i \right )} \right )} - y^{\left ( i \right )} \right )^2 +\lambda \left [ \rho\cdot \sum_{j=1}^{n} \left | \theta_j \right | + \left ( 1-\rho \right ) \cdot \sum_{j=1}^{n}\theta_j^2 \right ]$$
满足:$$\left{\begin{matrix}
\lambda >0\
\rho \in \left [ 0,1 \right ]\
\end{matrix}\right.$$
梯度下降
SGD:随机梯度,每拿到一个样本就进行梯度下降,一直循环
BGD:批量梯度
mini-batch:若干个样本的平均梯度作为更新方向
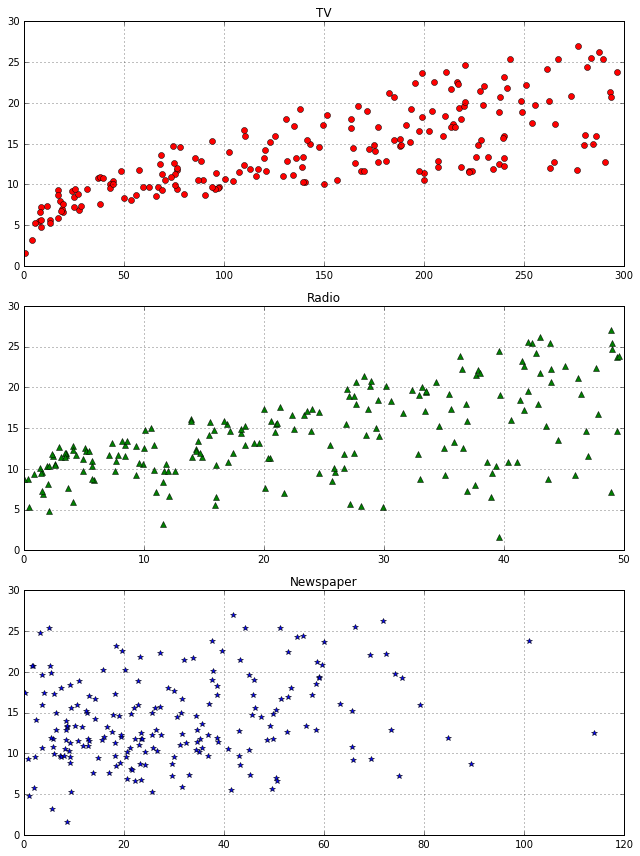
案例:广告费与销量关系分析
实验数据
数据集信息:数据共4列200行,前三列为输入特征,最后一列为输出特征。
输入特征:
- TV:在电视上投资的广告费用(以千元为单数,下同)
- Radio:在广播媒体上投资的广告费用
- Newspaper: 在报纸媒体上投资的广告费用
输出特征:
Sales:该商品的销量
读取数据
1 | import pandas as pd |
| Unnamed: 0 | TV | Radio | Newspaper | Sales | |
|---|---|---|---|---|---|
| 0 | 1 | 230.1 | 37.8 | 69.2 | 22.1 |
| 1 | 2 | 44.5 | 39.3 | 45.1 | 10.4 |
| 2 | 3 | 17.2 | 45.9 | 69.3 | 9.3 |
| 3 | 4 | 151.5 | 41.3 | 58.5 | 18.5 |
| 4 | 5 | 180.8 | 10.8 | 58.4 | 12.9 |
绘制TV/Radio/Newspaper与Sales关系图
1 | import matplotlib as mpl #设置环境变量 |
/home/nbuser/anaconda2_410/lib/python2.7/site-packages/matplotlib/font_manager.py:273: UserWarning: Matplotlib is building the font cache using fc-list. This may take a moment.
warnings.warn('Matplotlib is building the font cache using fc-list. This may take a moment.')
构建特征向量和标签列
1 | #创建包括特征向量名称的列表 |
| TV | Radio | Newspaper | |
|---|---|---|---|
| 0 | 230.1 | 37.8 | 69.2 |
| 1 | 44.5 | 39.3 | 45.1 |
| 2 | 17.2 | 45.9 | 69.3 |
| 3 | 151.5 | 41.3 | 58.5 |
| 4 | 180.8 | 10.8 | 58.4 |
1 | type(X) |
pandas.core.frame.DataFrame
1 | X.shape |
(200, 3)
1 | y=data['Sales'] |
0 22.1
1 10.4
2 9.3
3 18.5
4 12.9
Name: Sales, dtype: float64
构建训练集与测试集
1 | from sklearn.cross_validation import train_test_split |
1 | X_train.shape |
(150, 3)
1 | X_test.shape |
(50, 3)
1 | y_train.shape |
(150,)
1 | y_test.shape |
(50,)
sklearn的线性回归
1 | from sklearn.linear_model import LinearRegression |
1 | model |
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
1 | linreg.intercept_ |
2.87696662231793
1 | linreg.coef_ |
array([ 0.04656457, 0.17915812, 0.00345046])
1 | zip(feature_cols,linreg.coef_) |
[('TV', 0.046564567874150281),
('Radio', 0.17915812245088839),
('Newspaper', 0.0034504647111804412)]
预测
1 | y_pred = linreg.predict(X_test) |
array([ 21.70910292, 16.41055243, 7.60955058, 17.80769552,
18.6146359 , 23.83573998, 16.32488681, 13.43225536,
9.17173403, 17.333853 , 14.44479482, 9.83511973,
17.18797614, 16.73086831, 15.05529391, 15.61434433,
12.42541574, 17.17716376, 11.08827566, 18.00537501,
9.28438889, 12.98458458, 8.79950614, 10.42382499,
11.3846456 , 14.98082512, 9.78853268, 19.39643187,
18.18099936, 17.12807566, 21.54670213, 14.69809481,
16.24641438, 12.32114579, 19.92422501, 15.32498602,
13.88726522, 10.03162255, 20.93105915, 7.44936831,
3.64695761, 7.22020178, 5.9962782 , 18.43381853,
8.39408045, 14.08371047, 15.02195699, 20.35836418,
20.57036347, 19.60636679])
回归问题的评价测度
对于分类问题,评价测度(evaluation metrics)是准确率,但这种方法不适用于回归问题。我们使用针对连续数值的评价测度,有三种常用的针对线性回归的测度。
- 平均绝对误差(Mean Absolute Error, MAE)
- 均方差误差(Mean Squared Error, MSE)
- 均方根误差(Root Mean Squared Error, RMSE)
1 | from sklearn import metrics |
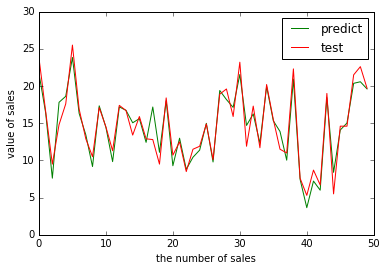
('RMSE by hand:', 1.4046514230328957)
作图
1 | plt.figure() |
结果分析
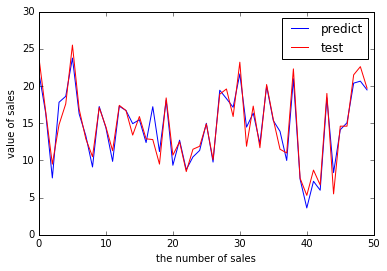
根据结果得模型:y=2.8769+0.0465xTV+0.1791xRadio+0.00345xNewspaper),发现Newspaper系数很小,再进一步观察Newspaper与Sales的关系散点图,发现其线性关系并不明显,因此将其去除。再看看线性回归预测的RMSE结果如何。
1 | X = data[['TV', 'Radio']] |
('RMSE by hand:', 1.3879034699382888)
1 | plt.figure() |
注意事项
本模型虽然简单,但它涵盖了机器学习的相当部分内容。如使用75%的训练集和25%的测试机,这往往是机器学习模型的第一步。分析结果的权值和特征数据分布,我们使用了简单的方法:直接删除;单这样做,仍然得到了更好的预测结果。
在机器学习中有“奥卡姆剃刀”原理,即:如果能够用简单模型解决问题,则不适用更为复杂的模型。因为复杂模型往往增加了不确定性,造成过多的人力和屋里成本,且容易过拟合。