Logistic回归
Logistic回归回归又称Logistic回归回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。
- 分类问题的首选算法。
- Logistic回归解决二分类问题,Softmax回归解决多分类问题。
Sigmoid函数
$$g\left(z\right) = \frac{1}{1+e^{-z}}=h_\theta \left(x\right) =g\left ( \theta ^Tx \right )=\frac{1}{1+e^{-\theta ^T x}}$$
$${g}’\left ( x \right ) = {\left ( \frac{1}{1+e^{-x}} \right )}’=\frac{e^{-x}}{\left ( 1+e^{-x} \right )^2}=\frac{1}{1+e^{-x}}\cdot \left ( 1- \frac{1}{1+e^{-x}} \right )=g\left ( x \right )\cdot \left ( 1-g\left ( x \right ) \right )$$
Logistic回归参数估计
假定:
$$P\left ( y=1|x;\theta \right ) = h_\theta \left ( x \right )$$,
$$P\left ( y=0|x;\theta \right ) = 1-h_\theta \left (x \right)$$
则:
$$P\left(y|x;\theta\right)=\left(h_\theta\left(x\right )\right)^y\left(1-h_\theta\left(x\right)\right)^{1-y}$$
似然函数:
$$L\left ( \theta \right ) = p\left ( \vec{y}|X;\theta \right ) = \prod_{i = 1}^{m}p\left ( y^\left ( i \right ) \right | {x^\left ( i \right )};\theta ) = \prod_{i=1}^{m}{\left ( h_\theta \left ( x^{\left ( i \right )} \right ) \right )^{y^\left ( i \right ) }} {\left ( 1-h_\theta\left ( x^\left ( i \right ) \right ) \right )^{1-y^\left ( i \right )}}$$
取对数得到:$$l\left ( \theta \right ) = logL\left ( \theta \right ) = \sum_{i=1}^{m}y^{\left ( i \right )}logh\left ( x^\left ( i \right ) \right ) + \left ( 1-y^\left ( i \right ) \right ) log\left ( 1-h\left ( x^\left ( i \right ) \right ) \right )$$
最后,对$$\theta$$参数求偏导:
$$\frac{\partial l\left ( \theta \right )}{\partial \theta_j} = \sum_{i=1}^{m}\left ( y^{\left ( i \right ) } -g\left ( \theta^Tx^{\left ( i \right )} \right )\right )\cdot x_j^{\left ( i \right )}$$
参数迭代
Logistic回归参数的学习规则:
$$\theta_j: = \theta_j + \alpha \left ( y^{\left ( i \right )} - h_\theta\left ( x^{\left ( i \right )} \right )\right )x_j^{\left ( i \right )}$$
损失函数
$$\therefore loss\left ( y_i,\hat{y}_i \right ) = -l\left ( \theta \right )$$,其中$$y_i\in \left { 0,1 \right }$$,$$\hat{y} = \left{\begin{matrix}
p_i & y_i=1 \
1-p_i & y_i = 0
\end{matrix}\right.$$
带入推导可得最终损失函数:$$\therefore loss\left ( y_i,\hat{y}i \right ) = -l\left ( \theta \right ) = - \sum{i=1}^{m}ln\left [ p_i^{y_i}\left ( 1-p_i \right )^{1-y_i} \right ] = \sum_{i=1}^{m}ln\left [ y_iln\left ( 1+e^{-f_i} \right ) + \left ( 1-y_i \right )ln\left ( 1+e^{f_i} \right )\right ]$$
Logistic回归的损失
$$y_i\in \left { -1,1 \right }$$
$$L\left ( \theta \right ) = \prod_{i=1}^{m}P_i^{\frac{\left ( y_i + 1 \right)}{2}}\left ( 1-P_i\right )^{\frac{-\left ( y_i-1 \right )}{2}}$$
$$loss\left ( y_i,\hat{y_i} \right )=\sum_{i=1}^{m}\left [ ln\left ( 1+e^{-y_i\cdot f_i} \right ) \right ]$$
广义线性模型Generalized Linear Model
- y不再只是正太分布,而是扩大为指数族中的任一分布;
- x -> g(x) -> y,连接函数g单调可导,例如逻辑回归中的$$g\left ( z \right ) = \frac{1}{1+e^{-z}}$$,拉伸变换$$g\left(z\right )=\frac{1}{1+e^{-\lambda z}}$$

Softmax回归
- K分类,第k类的参数为$$\vec{\theta_k}$$,组成二维矩阵$$\theta _{k\times n}$$
- 概率:$$p\left ( c=kx;\theta\right)=\frac{exp\left ( \theta_k^T x \right )}{\sum_{l=1}^{K}exp\left ( \theta_l^T x \right )}$$, 其中k=1,2,……,K
- 似然函数:$$ L\left ( \theta \right ) =\prod_{l=1}^{m}\prod_{k=1}^{K} p\left (c=k|x^{\left ( i \right )} ;\theta \right )^{y_k^\left ( i \right )}
=\prod_{l=1}^{K}\prod_{k=1}^{K}\left( exp\left ( \theta_k^T x^{\left ( l \right )} \right ) / \sum_{l=1}^{K}exp\left ( \theta^T_l x^\left ( l \right ) \right )\right )^{y_k^{\left ( i \right )}} $$ - 对数似然:
$$J_m\left ( \theta \right ) = ln L\left ( \theta \right ) = \sum_{i=1}^{m}\sum_{k=1}^{K}y_k^{\left ( i \right )}\cdot \left ( \theta^T_kx^{\left ( i \right )} - ln \sum_{l=1}^{K}exp\left ( \theta^T_l x^{\left ( i \right )} \right )\right )$$,
$$J\left ( \theta \right ) = \sum_{k=1}^{K}y_k\cdot \left ( \theta^T_k x - ln\sum_{l=1}^{K}exp\left ( \theta_l^Tx \right )\right )$$ - 随机梯度:
$$\frac{\partial J\left ( \theta \right )}{\partial \theta_k} = \left ( y_k - p\left ( y_k|x,\theta \right ) \right )\cdot x$$
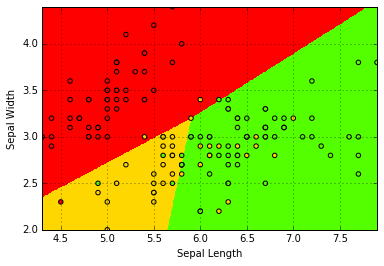
鸢尾花分类
实验数据
鸢尾花数据集是最有名的模式识别测试数据,1936年模式识别先驱Fisher在其论文“The use of multiple measurements in taxonomic problems” 使用了它。数据集包括3个鸢尾花类别,每个类别有50个样本,其中一个类别与另外两类线性可分,而另外两类不能线性可分。
数据描述
该数据集包括150行,每行为1个样本,每个样本共有5个字段,分别是花萼长度,花萼宽度,花瓣长度,花瓣宽度,类别。其中类别包括Iris Setosa, Iris Versicolour,Iris Virginica三类,前四个字段的单位为cm。
实验代码
1 | # -*- coding: utf-8 -* |
1 |
|
'Accuracy: 76.67%'
结果分析
- 仅用花萼长度和宽度,在150个样本中,有115个分类正确,正确率为76.67%
- 使用四个特征,试验后发现有144个样本分类正确,正确率为96%.
案例跟踪
1 | # -*- coding: utf-8 -* |
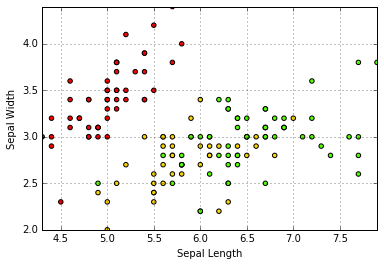
1 | 'Accuracy: %.2f%%' % (100*float(c)/float(len(result))) |
'Accuracy: 84.21%'
分析:
- 第四节使用训练集测试,结果正确性有误
- 本实验分训练集和测试集,准确率为84.21%